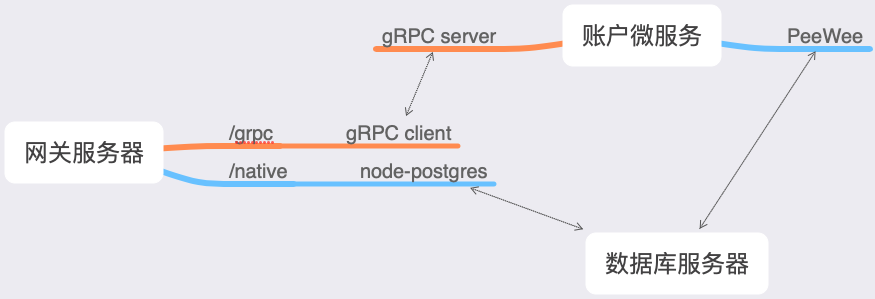
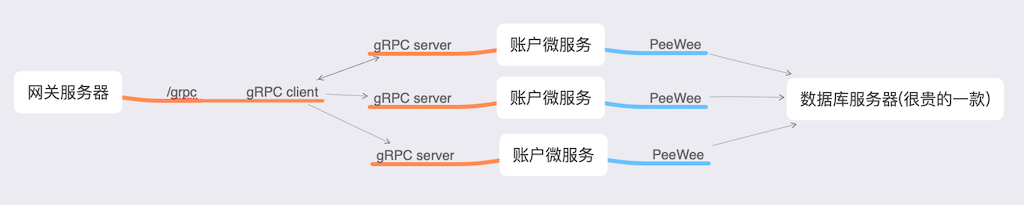
context
继续昨天的内容,今天把twisted,pika整理一下
Let’s do it
twisted用来处理socket,pika用来和rabbitMQ做交互
twisted
twisted的官方文档介绍了很多用法,一开始我还以为twisted是个网络框架,在踩了一些坑,成功集成了pika之后,才发现自己错了。它更像一个runloop(loop)
在loop中注册事件,注册循环,来完成异步操作,循环操作等。和嵌入式的main()里面的那个while(1)很像,我就称他为:大循环吧
from twisted.internet import reactor
# 大循环就这么运行
reactor.run()
在大循环里面做点儿其他的事情:
from twisted.internet import reactor,task
# 用center实例来监听端口号为8123的TCP,center的具体实现后面再说~
reactor.listenTCP(8123, center)
# 在大循环中每0.01秒执行一次handle_message(),参数是queue_object
l = task.LoopingCall(handle_message, queue_object)
l.start(0.01)
reactor.run()
那么言归正传,先用twisted来搭建一个tcp服务器,先直接贴个代码:
socketEntity.py:
import datetime
from twisted.internet.protocol import connectionDone
from twisted.protocols.basic import LineReceiver
class SocketEntity(LineReceiver):
def __init__(self, device_list, addr):
#全局socket列表的 引用
self.global_socket_list_reference = device_list
#更新时间
self.updateTime = datetime.datetime.now()
#地址
self.address = addr.host
#收到了数据
def dataReceived(self, data):
print data
#连接建立
def connectionMade(self):
print "new connection from {}".format(self.address)
self.sending_connection_status(True)
if self.address in self.global_socket_list_reference.keys():
pass
else:
self.global_socket_list_reference[self.address] = self
#连接丢失
def connectionLost(self, reason=connectionDone):
print "connection {} lost".format(self.address)
self.sending_connection_status(False)
if self.address in self.global_socket_list_reference.keys():
del self.global_socket_list_reference[self.address]
#更新远程数据库状态
def sending_connection_status(self, online):
pass
socketServer.py:
import json
from twisted.internet.protocol import Factory
from socketEntity import SocketEntity
from twisted.internet import reactor, protocol
from twisted.internet import defer
from twisted.internet import task
class DeviceCenter(Factory):
def __init__(self):
这个就是全局socket列表
self.devices = {}
def send_cmd(self, addr, cmd):
if addr in self.devices:
self.devices[addr].sendLine(cmd)
else:
print "no connection"
# 这个是必须要的
def buildProtocol(self, addr):
return SocketEntity(self.devices, addr)
center = DeviceCenter()
try:
#增加监听端口的事件
reactor.listenTCP(8123, center)
reactor.run()
except KeyboardInterrupt:
print "socket stop manually"
except Exception as e:
print "socket error:", e.message
我觉得,光靠注释应该差不多可以知道这个在干嘛。其实这个和twisted官方的tcp文档基本一样,如果发现跑不起来(因为删了pika相关的东西后,没有再调试)可以去官方文档重新搞一份
说说我的理解~
前面说到了twisted是个事件驱动的框架,所以会注册很多的事件,比如注册一个监听事件,注册一个延迟事件,注册一个循环事件~
注册监听事件reactor.listenTCP(8123, center),我觉得这个方法可能注册了很多小事件,这些小事件会调用DeviceCenter中的buildProtocol(),以及相应Protocol中的一些函数,比如dataReceived,connectionMade,connectionLost等
pika
这个框架就是rabbitMQ client的python版本,通过这个库,可以轻松的发送message到rabbitMQ,也可以轻松的监听rabbitMQ
官方文档就写了很简单的用法
官方文档里面对连接认证这一块描述的还是挺简单的,但是通过pycharm的自动补全,或者查看源代码,就能知道如何设置连接的各种参数以及认证参数
官方sender.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
官方receive.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
很明显,这里pika很牛逼,有他的start_consuming()会阻塞整个主线程,会一直监听queue,直到消费者出现异常,或者用户手动break。这个对于后面在数据库服务器做,根据rabbitMQ的消息来修改数据库中相应数据这个功能非常友好。基本来说,靠这个例子就行了。
twisted+pika
因此,pika的start_consuming()是万万不能用到twisted中的
好在,pika的官方文档刚刚好给出了twisted的消费者example
我也贴一遍:
# -*- coding:utf-8 -*-
import pika
from pika import exceptions
from pika.adapters import twisted_connection
from twisted.internet import defer, reactor, protocol,task
@defer.inlineCallbacks
def run(connection):
channel = yield connection.channel()
exchange = yield channel.exchange_declare(exchange='topic_link', exchange_type='topic')
queue = yield channel.queue_declare(queue='hello', auto_delete=False, exclusive=False)
yield channel.queue_bind(exchange='topic_link',queue='hello',routing_key='hello.world')
yield channel.basic_qos(prefetch_count=1)
queue_object, consumer_tag = yield channel.basic_consume(queue='hello',no_ack=False)
#在主循环中增加一个read的任务,周期为0.01秒
l = task.LoopingCall(read, queue_object)
l.start(0.01)
@defer.inlineCallbacks
def read(queue_object):
#消费一下
ch,method,properties,body = yield queue_object.get()
if body:
print(body)
yield ch.basic_ack(delivery_tag=method.delivery_tag)
parameters = pika.ConnectionParameters()
cc = protocol.ClientCreator(reactor, twisted_connection.TwistedProtocolConnection, parameters)
d = cc.connectTCP('hostname', 5672)
# 这个我还没有去了解是干嘛的
d.addCallback(lambda protocol: protocol.ready)
d.addCallback(run)
reactor.run()
虽然我最后写的和这个不太一样,但是踩了一下午的坑,才把它做对了~
下面贴一下我的server的代码。这个socket server的作用是,http server收到了http request之后,向rabbitMQ发送了一个消息,内容是向某个设备(address)发送一条命令(cmd),twisted tcp server收到了rabbitMQ中的消息后,作出send_cmd的操作
socketServer.py:
import json
from twisted.internet.protocol import Factory
from socketEntity import SocketEntity
from twisted.internet import reactor, protocol
from twisted.internet import defer
from twisted.internet import task
# 注意这里需要新建一个mqConfigure.py 并把相应的设置参数写在里面
from mqConfigure import *
import pika
from pika.adapters import twisted_connection
class DeviceCenter(Factory):
def __init__(self):
self.devices = {}
存一个连接的引用保险保险
self.connection = None
def send_cmd(self, addr, cmd):
if addr in self.devices:
self.devices[addr].sendLine(cmd)
else:
print "no connection"
def buildProtocol(self, addr):
return SocketEntity(self.devices, addr)
@defer.inlineCallbacks
def handle_message(self, data):
# 获取消息,并处理消息
ch, method, properties, body = yield data.get()
load_data = json.loads(body)
addr = load_data.get("address")
cmd = str(load_data.get("cmd"))
self.send_cmd(addr, cmd)
yield ch.basic_ack(delivery_tag=method.delivery_tag)
@defer.inlineCallbacks
def setup_mq_listener(self, conn):
#这个时候rabbitMQ的tcp已经连接成功了,所以做后面的事情都没问题
channel = yield conn.channel()
yield channel.queue_bind(exchange='exchange', queue=MQ_QUEUE, routing_key=MQ_QUEUE)
yield channel.basic_qos(prefetch_count=1)
queue_object, consumer_tag = yield channel.basic_consume(queue=MQ_QUEUE, no_ack=False)
#因为start_consuming()是阻塞的,所以就使用twisted里面常用的task手段来实现一个监听的操作(也挺像轮询的)
l = task.LoopingCall(self.handle_message, queue_object)
l.start(0.01)
center = DeviceCenter()
try:
reactor.listenTCP(8123, center)
# 连接rabbitMQ的参数
parameters = pika.ConnectionParameters(host=MQ_HOST, port=MQ_PORT, virtual_host=MQ_VHOST,
credentials=pika.PlainCredentials(MQ_USERNAME, MQ_PASSWORD))
cc = protocol.ClientCreator(reactor, twisted_connection.TwistedProtocolConnection, parameters)
# 我把它理解为异步操作的task对象,可以增加回调
d = cc.connectTCP(MQ_HOST, MQ_PORT)
#我依然不知道这个是干嘛的
d.addCallback(lambda protocol: protocol.ready)
# connectTCP成功之后的回调,设置监听MQ
d.addCallback(center.setup_mq_listener)
reactor.run()
except KeyboardInterrupt:
print "socket stop manually"
print "cleared data"
except Exception as e:
print "socket error:", e.message
print "cleared data"
那天花了比较多的时间浪费在理解twisted的运行机制上,所以让我感觉twisted非常难的样子。现在整理了一下,感觉其实并不难~
End
今天差不多就到这粒
明天或者后天,来写写数据库服务器如何处理rabbitMQ的内容,并修改Django的数据库;以及把整个系统做成分布式时需要考虑的一些细节吧~